Designing a query execution engine#
Authored by Hammad Bashir Sanket Kedia Sicheng Pan
Authored by Hammad Bashir Sanket Kedia Sicheng Pan
As an Open Source company we believe in giving credit where credit is due. The majority of the technical ideas in this post were not invented at Chroma, and we reference research and systems from which we have generously borrowed techniques and architecture.
Distributed Chroma is a multi-tenant system. Query and Compactor nodes serve queries and build indexes for multiple tenants. By leveraging multi-tenancy we can maximize utilization of nodes in our system, resulting in lower costs for our users. However, building with multi-tenancy in mind presents the challenge of how to optimally structure, dispatch, and schedule work such that resources are fairly used across all tenants.
This constraint led us to search for an execution model for Query and Compaction nodes. We needed an execution model that would allow us to:
Luckily, database researchers and practitioners have a well understood set of execution models to learn and borrow from. A common separation between these execution models is whether they are pull-based or push-based. Let’s consider a basic SQL query in order to explain the difference.
This may result in a query plan that scans the table, performs the filter, and then selects on the column we care about (field A).
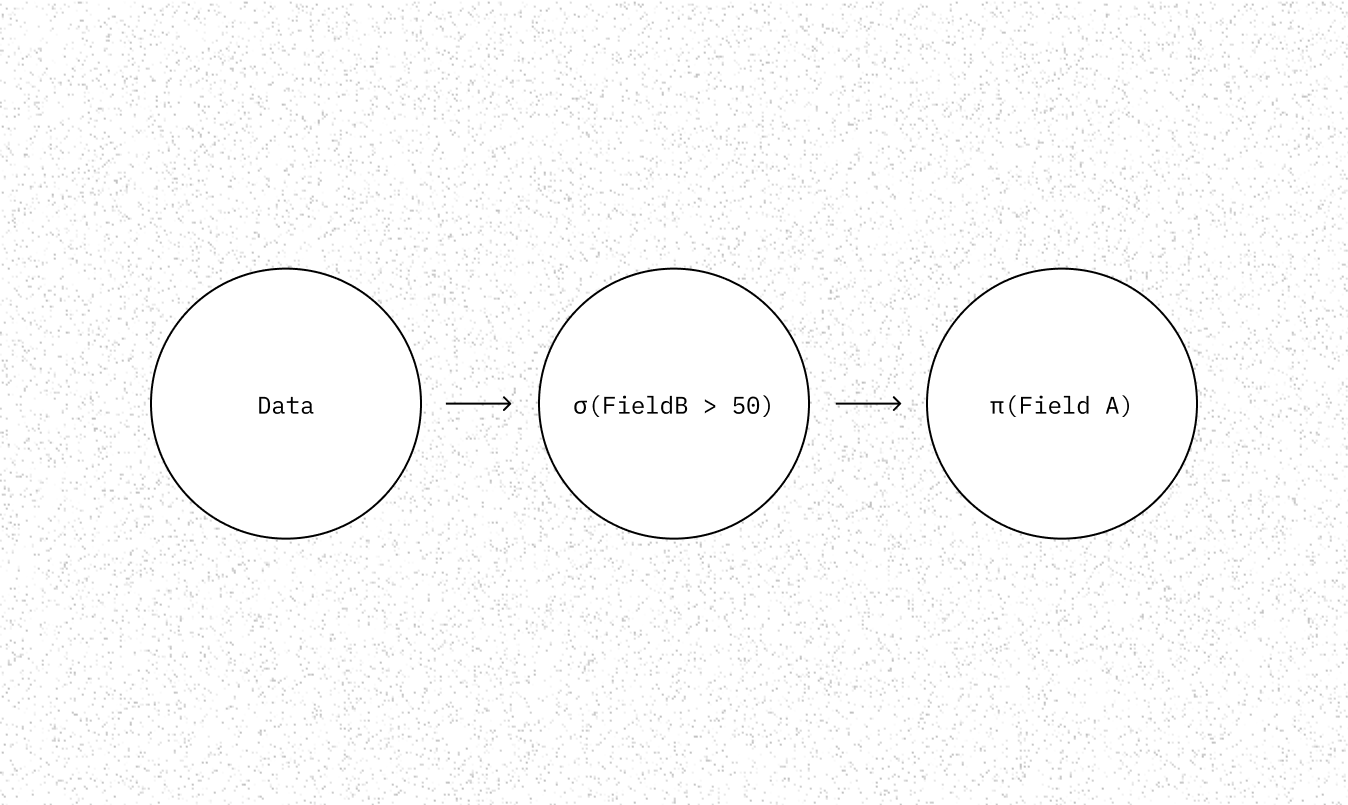
In a pull-based model (often called the Volcano model) each operator pulls data from its predecessor - as a tuple or a vector. For example, the select operator above can be viewed as the following function.
This operator first pulls data from an input iterator, and outputs an iterator itself. Expressing an entire query plan is relatively straightforward in this model, you can just recursively chain operators.
In a push-based model each operator has its input pushed into it from some other source, rather than pulling an input itself.
This distinction results in an important property for our system - the control flow of the entire query in a push-based model is moved off of the stack.
In a pull based model, the flow is held implicitly on the stack, whereas in a push based model, we are able to have the logic for moving data between operators as explicit code. Mark Raasveldt from DuckDB has a great talk on the subject which we were heavily inspired by.
By moving the control flow off of the stack and into explicit code, as well as being able to push data into operators, the ability to dynamically parallelize, interrupt, and schedule a query becomes substantially easier.
In many many execution systems, parallelism is baked into the plan via exchange operators. The plan will take a query such as:
Which has a simple zero-parallelism plan, and turn it into a plan with a fixed degree of parallelism by partitioning the data.
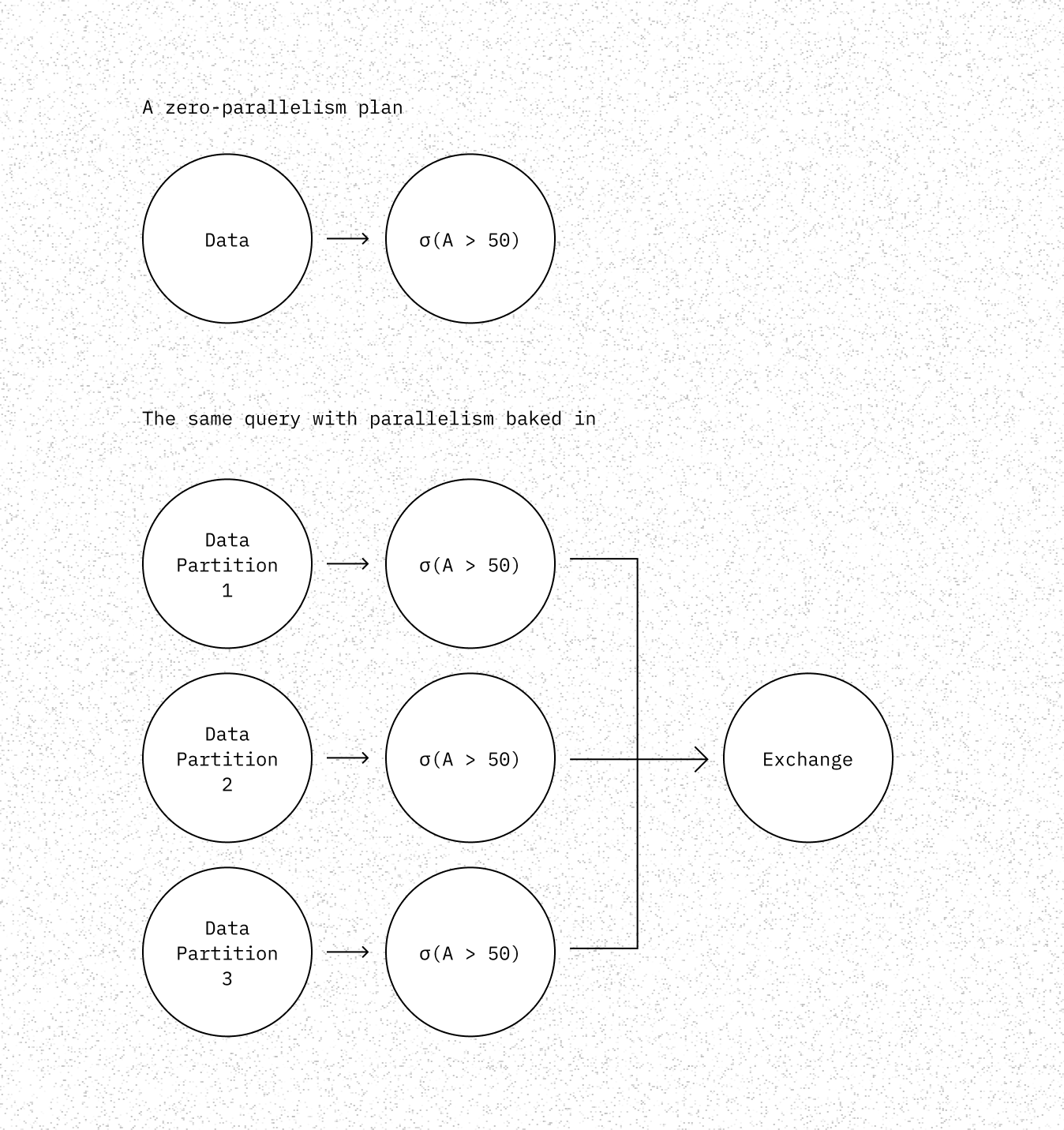
This approach has the drawback of having a fixed degree of parallelism that cannot be adjusted dynamically. If during a query more resources become available, or another query needs resources, we cannot adjust the resource usage of an ongoing query in response.
In “Morsel-Driven Parallelism” the authors present a system capable of dynamically parallel, interruptible query execution [1]. In contrast with the fixed-parallelism approach, the core idea is to reframe the query execution as parallel over slices of the data they call a “morsel”. These morsels can then be executed with a dynamic degree of parallelism. The morsels can be viewed as runtime-created partitions.
For example, when performing a hash join, the hash probe step can be made parallel. This is accomplished by dividing the data into a set of morsels, homogenous in size, and then performing the hash probe in parallel. This leads to a potentially high degree of intra-query parallelism.
Core to the morsel-driven approach, are two components - a query execution orchestrator [2], and a dispatcher. The dispatcher is used by a pool of worker threads to receive a morsel of data to process. Worker threads request work from the dispatcher, which acts as a scheduler for the system. The dispatcher can be aware of system constraints, as well as other ongoing queries and intelligently schedule work to worker threads. The query execution orchestrator is responsible for scheduling work over morsels to the dispatcher and advancing through the query plan for a given query.
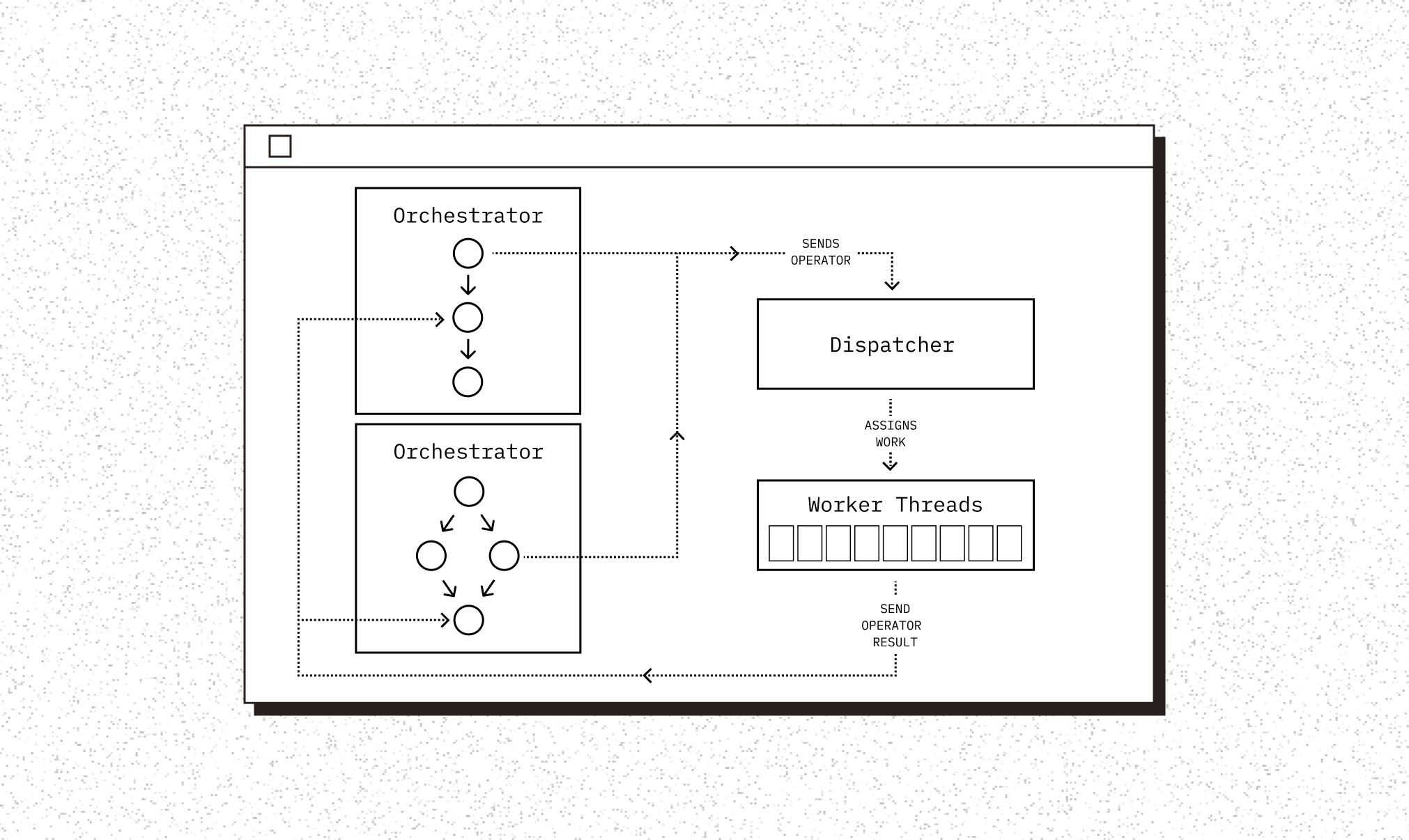
This approach gives us exactly what we were looking for - a way to ensure QoS for tenants across queries through scheduling, the ability to dynamically increase and reduce parallelism with intelligent scheduling and an operator model that can evolve over time.
Chroma’s implementation is a push-based, morsel-driven execution engine.
Chroma has a much smaller API than supporting arbitrary SQL, and so we can view the Chroma API as a handful of static logical plans, with a handful of static physical plans.
For example, a call to collection.get() or collection.query() would result in the following plans.
View Code: chromadb/execution/expression/plan.py
Once the plan arrives on the query node, it is mapped to its corresponding orchestrator. Each orchestrator essentially executes a physical plan that is known in advance. For example, a call to collection.query() results in the KNN orchestrator being dispatched. The plan pulls any unindexed from the log and brute forces it, while querying the underlying KNN index.
The log is partitioned into morsels and any subsequent operators use the morsel driven approach for operating on the log data.
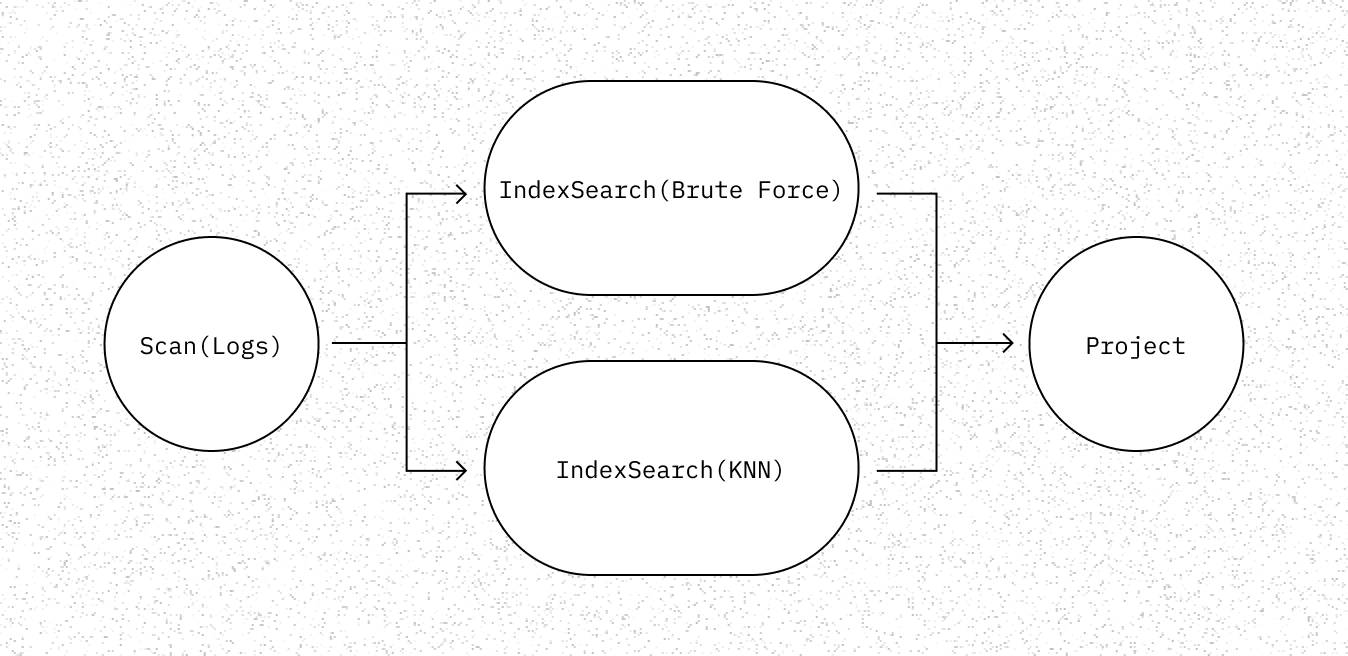
View Code: rust/worker/src/execution/orchestration/hnsw.rs#L52
The orchestrator here is conceptually a state machine that tracks dependencies between tasks and then sends operators to the dispatcher. It advances through the query plan by sending a task, which is an operator along with its inputs to the dispatcher. The dispatcher acts as a scheduler for work on worker threads. The dispatcher is where we can add control logic for controlling both inter-query as well as intra-query parallelism - accounting for constraints such as fairness between tenants and system resource utilization.
Our Rust binaries use Tokio as its async runtime. Each worker thread is a standalone Tokio runtime - meant for computationally expensive operators. Tasks are sent from the orchestrator on the main multi-threaded Tokio runtime to the dispatcher, the dispatcher is used by workers to fetch work.
Our query execution framework provides us with a foundation to iterate on various future improvements such as tenant fairness, intelligent work scheduling, work stealing, query optimization, NUMA-awareness, and more. If you are interested in working on challenges like these - we are hiring!
Footnotes
[1] Morsel-driven parallelism also has many other potential benefits - such as NUMA awareness - however we do not leverage them yet.
[2] The paper calls this the QEPobject. What we call an “orchestrator” performs many of the same tasks.