Today, millions of developers already use Chroma as the retrieval component in their AI applications. Chroma is deployed in everything from weekend projects to large-scale production use.
Though Chroma already works great for many use-cases, developers have been asking us for Chroma in the cloud since day one. They want to be able to use Chroma through an API, without having to manage the infrastructure, and to scale costs with their usage. This requires building a multi-tenant architecture with fairness considered throughout. Enterprise customers additionally want to keep their data in their own VPCs, requiring us to build in a strong data-plane, control-plane separation to enable BYOC.
Designing a serverless retrieval system is challenging; there are many trade-offs and constraints unique to retrieval for AI applications which must be carefully considered. In particular, retrieval workloads for AI applications differ significantly from traditional search workloads. Everything must be designed with the requirements of AI applications in mind.
Retrieval is unique#
Retrieval has much in common with traditional search systems, including keyword and full-text search and metadata filtering, while adding the ability to search over dense vector embeddings. While we've always known that retrieval workloads for AI are unique, in September 2023 we evaluated several months of anonymized telemetry from existing deployments of Chroma, and talked with hundreds of developers about their constraints and use-cases.
What we learned helped us to understand how requirements for retrieval systems differ from traditional search.
Classic search systems often assume that:
- Your data is spread across a small number of indexes.
- The access across indexes is fairly uniform.
- The application needs very low latency search.
- A single index can grow to billions of records.
- A large percentage of your queried data fits within memory.
We found that most of our customers:
- Had potentially millions of indexes as opposed to a handful, often many per user of their application.
- Were insensitive to moderate latencies of 35-100ms and occasional latency spikes, often due to their already high end to end latency after multiple language model calls.
- Had indices with moderate scale - from hundreds of thousands to several million records.
- That the access pattern across collections followed a power law - the majority of indices were infrequently accessed, with a handful dominating.
This final point is particularly important to making retrieval cost-effective . Search indexes are often maintained in-memory, but the power-law access patterns of retrieval workloads, as well as their less stringent latency requirements, mean that we can effectively leverage object storage to deliver a cost-effective serverless retrieval system without compromising on the performance requirements demanded by our users.
Object-storage native Chroma#
Modern scalable, distributed data infrastructure relies on the separation of storage and compute , and the separation of read and write paths . Chroma's serverless architecture is based on object storage as a shared-storage layer for query nodes which resolve user queries, and compactor nodes, which asynchronously build indexes in the background and persist them to object storage.
By leveraging object storage as a shared storage layer for stateless query nodes, we dramatically reduce the cost of serving vector and full-text indexes.
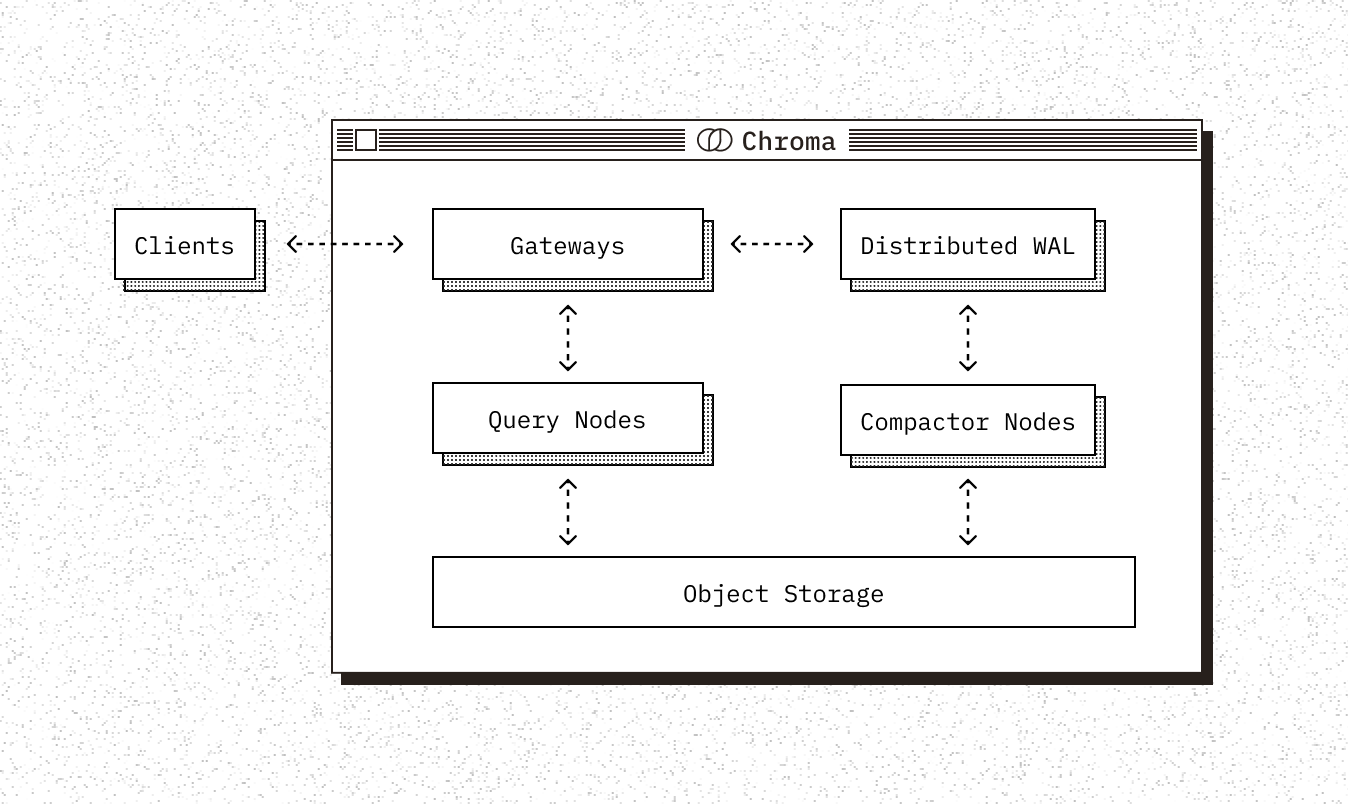
Gateways: Handle cluster routing and query orchestration. Query nodes: Serve indices from object storage and cache. Compactor nodes: build indices and persist them to object storage. Distributed WAL: Used to provide durability to the system ahead of a compaction.
Object storage is an order of magnitude cheaper than a replicated set of SSDs, and has incredibly high parallel throughput (1+ GB/s), at the cost of higher latencies (35-100ms) compared to SSD. These characteristics require careful attention to the design of the storage engine's underlying storage design, query execution, and caching strategies.
Our custom storage engine, written in Rust, leverages the fast-growing Arrow data format for its storage, and is designed to minimize both read/write amplification between query/compactor nodes as well as cache invalidation between compactions.
By adopting Arrow, we also get a robust feature set, interoperability with parquet, and cross-language support. This makes it easy to add background jobs for analytical workloads such as clustering and deduplication, while maintaining development velocity.
In order to mitigate the higher latencies of object storage, we leverage caching, both on SSD and in memory, to shift the latency curve for recently accessed (warm) collections.
Using object storage allows us to delegate almost all aspects of storage management, such as replication, durability, backup, and scaling, significantly reducing the operational burden on the Chroma team. Because we don't have to think about RAFT or PAXOS, we can continue to focus on building the best, easiest to use, most accurate, and most cost-effective hosted retrieval system for AI applications.
Our distributed and serverless architecture is available under the Apache 2.0 license.
Onwards#
AI is a new kind of software. Our mission at Chroma is to accelerate the useful and creative applications of AI, by giving developers the best tools and infrastructure. It's still very early, and we're excited for the years ahead.
-> Chroma engineering team:
Hammad Bashir, Kyle Diaz, Robert Escriva, Cooper Gamble, Jeff Huber, Max Isom, Sanket Kedia, Drew Kim, Tanuj Nayak, Sicheng Pan, Philip Thomas, Itai Smith